




Sebelumnya kita sudah bahas mengenai pendugaan interval, berikut kita akan terapkan pada dua contoh, penerapan interval parameter mean untuk sampel ukuran besar dan sampel ukuan kecil.
Contoh penerapan parameter mean sampel ukuran besar n≥30 dan populasi tidak terbatas.
Suatu lembaga penelitian di Jakarta, mengadakan survei sederhana dengan tujuan utama mengetahui besarnya rata-rata pengeluaran para wisatawan mancanegara yang berkujung ke Bali. Untuk itu diambil sampel acak 500 wisatawan mancanegara yang menginap di beberapa hotel bintang lima di Nusa Dua Bali. Dari survey diperoleh bahwa rata-rata pengeluaran adalah 2.000 dolar per wisatawan untuk setiap kali berkunjung ke Bali yang terdiri atas pengeluaran untuk hotel, transportasi, makan dan barang-barang seni. Bila diketahui simpangan baku pengeluaran untuk semua wisatawan yang berkunjung ke bali adalah 250 dolar, buatlah interval kepercayaan 99% untuk memperkirakan berapa sesungguhnya rata-rata pengeluaran per wisatawan mancanegara untuk setiap kali berkunjung ke Bali?
Kasus di atas adalah pendugaan parameter mean dengan ukuran sampel besar, sehingga dibutuhkan tabel Z.
Jawab :
Jumlah populasi tidak diketahui berarti tidak terbatas (tidak dibutuhkan faktor koreksi untuk menghitung simpangan baku sampel rata-rata)
n = 500
Rata-rata = 2000
Simpangan baku = 250
Interval kepercayaan = 99%
1 - a = 99% --> a = 1% = 0,01 --> a/2 = 0,005 --> Za/2 = 2,58
Nilai rata-rata dari sampel rata-rata = 2000
Simpangan baku dari sampel rata-rata =
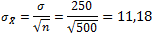
Jadi
 Jadi interval kepercayaan 99% untuk memperkirakan berapa sesungguhnya rata-rata pengeluaran per wisatawan mancanegara untuk setiap kali berkunjung ke Bali adalah berkisar antara 1971,16 dolar dan 2028,84 dolar.
Jadi interval kepercayaan 99% untuk memperkirakan berapa sesungguhnya rata-rata pengeluaran per wisatawan mancanegara untuk setiap kali berkunjung ke Bali adalah berkisar antara 1971,16 dolar dan 2028,84 dolar.
Contoh penerapan parameter mean sampel ukuran besar n<30 dan ukuran populasi terbatas.
Suatu sampel acak berukuran 10 mempunyai rata-rata 9,5 dan simpangan baku 3,24. Buatlah interval kepercayaan 90% untuk menduga rata-rata dari populasi tersebut!
Kasus di atas adalah kasus populasi tidak terbatas sehingga tidak dibutuhkan faktor koreksi untuk menghitung simpangan baku sampel rata-rata. Dan ukuran sampel < 30 sehingga digunakan tabel - t.
Jumlah populasi tidak diketahui berarti tidak terbatas (tidak dibutuhkan faktor koreksi untuk menghitung simpangan baku sampel rata-rata)
n = 10 --> df = 10-1=9
Rata-rata = 9,5
Simpangan baku = 3,24
Interval kepercayaan = 90%
1 - a = 90% --> a = 10% = 0,01 --> a/2 = 0,05 --> t(0,05;9) = 1,833
Nilai rata-rata dari sampel rata-rata = 9,5
Simpangan baku dari sampel rata-rata = 8

Jadi

Jadi interval kepercayaan 90% untuk menduga rata-rata dari populasi tersebut adalah berkisar antara 7,63 sampai 11,73.
Jika kasus di atas diketahui jumlah populasinya, maka simpangan baku harus dikalikan dengan faktor koreksi. Yaitu :
contoh sampel besar di atas jika populasi diketahui sejumlah 1000, sehingga simpangan baku seharusnya :

contoh sampel kecil di atas jika populasi diketahui sejumlah 50, sehingga simpangan baku seharusnya :

Dan selanjutnya untuk menghitung interval kepercayaan sama dengan sebelumnya. Hanya saja mengganti nilai simpangan baku yang sudah dikalikan dengan faktor koreksi.
by MEYF ^_^













































