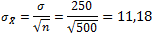Berikut kita berikan contoh penggunaan pendugaan interval parameter proporsi untuk sampel ukuran besar dan sampel ukuran kecil.
Contoh penerapan pendugaan interval parameter proporsi ukuran sampel besar dan ukuran populasi tidak diketahui.
Seorang pejabat bank ingin mengetahui lebih lanjut persentase debitur yang menunggak angsuran rumah pada suatu tahun tertentu. Dari sampel yang dikumpulkan sebanyak 1.000 nomor debitur ternyata ada 105 debitur yang tidak melunasi kewajibannya untuk membayar angsuran. Buatlah interval kepercayaan 90% untuk menduga berapa sesungguhnya debitur yang tidak melunasi angsuran rumah!
Kasus di atas adalah untuk ukuran sampel besar. Sehingga menggunakan tabel-Z.
Jawab :
Ukuran populasi tidak diketahui sehingga simpangan baku tidak dikalikan dengan faktor koreksi.
X = debitur yang tidak melunasi kewajibannya membayar angsuran = 1000
n = sampel debitur yang dikumpulkan = 105
p = X / n = 105 / 1000 = 0,105Interval kepercayaan 90%
1 - a = 90% --> a = 10% = 0,05 --> a/2 = 0,025 --> Za/2 = 1,646
Rata-rata sampel proporsi = p = 0,105
Simpangan baku sampel proporsi =

Jadi

Jadi interval kepercayaan 90% untuk menduga berapa sesungguhnya debitur yang tidak melunasi angsuran rumah adalah berkisar antara 8,9% hingga 12,1%.
Contoh penerapan pendugaan interval parameter proporsi ukuran sampel kecil dan ukuran populasi tidak diketahui.
Sampel acak 25 ibu-ibu arisan dan ternyata terdapat 10 orang yang berhak telah dipilih sebagai panitia suatu acara. Buatlah interval kepercayaan 95% untuk menduga berapa orang ibu-ibu yang berhak menjadi panitia acara tersebut?
Kasus di atas adalah untuk ukuran sampel kecil. Sehingga menggunakan tabel-t.
Jawab :
Ukuran populasi tidak diketahui sehingga simpangan baku tidak dikalikan dengan faktor koreksi.
X = Ibu-ibu arisan yang dipilih menjadi panitia = 10
n = 25 --> df = n-1 = 25-1= 24
p = X / n = 10 / 25 = 0,4
Interval kepercayaan 95%
Simpangan baku sampel proporsi =



by MEYF ^_^
Contoh penerapan pendugaan interval parameter proporsi ukuran sampel kecil dan ukuran populasi tidak diketahui.
Sampel acak 25 ibu-ibu arisan dan ternyata terdapat 10 orang yang berhak telah dipilih sebagai panitia suatu acara. Buatlah interval kepercayaan 95% untuk menduga berapa orang ibu-ibu yang berhak menjadi panitia acara tersebut?
Kasus di atas adalah untuk ukuran sampel kecil. Sehingga menggunakan tabel-t.
Jawab :
Ukuran populasi tidak diketahui sehingga simpangan baku tidak dikalikan dengan faktor koreksi.
X = Ibu-ibu arisan yang dipilih menjadi panitia = 10
n = 25 --> df = n-1 = 25-1= 24
p = X / n = 10 / 25 = 0,4
Interval kepercayaan 95%
1 - a = 95% --> a = 5% = 0,05 --> a/2 = 0,025 --> t(0,025;24) = 2,064
Rata-rata sampel proporsi = p = 0,4Simpangan baku sampel proporsi =
Jadi
Jadi interval kepercayaan 95% untuk menduga berapa orang ibu-ibu yang berhak menjadi panitia acara tersebut adalah berkisar antara 19,8% hingga 60,2%.
Jika kasus di atas diketahui jumlah populasinya N, maka simpangan baku harus dikalikan dengan faktor koreksi :
Dan selanjutnya untuk menghitung interval kepercayaan sama dengan sebelumnya. Hanya saja mengganti nilai simpangan baku yang sudah dikalikan dengan faktor koreksi.
by MEYF ^_^