

Statistic do not speak for themselves
Milton Friedman

Statistics is the grammar of science
Karl Pearson

Statistics : The Mathematical Theory of Ignorance
Morris Kline

join di youtube Mellyna Eka Yan Fitri ya...
kunjungi : https://www.youtube.com/@mellynayan
Sabtu, 20 September 2014
Rabu, 27 Agustus 2014
UJI HETEROSKEDASTISITAS
Uji asumsi klasik berikutnya adalah uji heteroskedastisitas. Dalam analisis regresi, salah satu asumsi yang harus dipenuhi adalah varians error masing-masing variabel bebas harus konstan. Hal ini dikenal dengan istilah Homoskedastisitas. Selain itu dikenal istilah Heteroskedasitas lawan dari Homoskedastisitas, yaitu keadaan dimana terjadinya ketidaksamaan varian dari error untuk semua pengamatan setiap variabel bebas pada model regresi.
Untuk menguji ada atau tidaknya Heteroskedastisitas dapat dilakukan melalui beberapa uji, yaitu :
- Uji Spearman's rho.
- Uji Glejser.
- Uji Park.
- Uji melalui pola grafik
Secara umum persamaan regresi linear berganda adalah
Y = a + b1X1 + b2X2 + error
Sedangkan Y prediksi atau mean Y adalah
Y' = E(Y) = a + b1X1 + b2X2
Untuk metode ke-4, melalui pola grafik, ada beberapa hal yang sering muncul, yaitu :
1. Jika data berdistribusi Poisson seperti jumlah hari sakit karyawan dalam sebulan. Maka pola grafiknya adalah :


3.Jika data adalah data ekonomi dan bisnis biasanya adalah model multiplikatif (perkalian), sehingga fungsi regresi yang terbentuk adalah hasil perkalian antara Y' dengan error, yaitu Y = E(Y) * error = Y' * error
Maka pola grafiknya adalah sebagai berikut :

Ada beberapa indikator yang dapat menyebabkan terjadinya heteroskedastisitas, yaitu :
- Kesalahan input nilai dari variabel tidak bebas Y.
- Biasanya ada pada data Time Series dan data ekonomi.
- Adanya manipulasi data.
- Distribusi data yang tidak normal seperti Poisson dan Binomial.
Apa solusinya jika terjadi heteroskedastisitas?
- Menambah atau mengganti data sampel baru.
- Melakukan transformasi variabel bebas X terhadap variabel tidak bebas Y.
- Menggunakan metode estimasi yang lebih Advance seperti GLS (Generalized Least Squares) dan WLS (Weighted Least Squares)
- Menggunakan model regresi linear berganda dimana nilai residualnya mengikuti Autoregressive Conditionally Heteroscedastic orde 1 (ARCH(1) ) atau mengikuti Generalized ARCH(1).
Next Session adalah contoh pengujian Heteroskedastisitas dengan IBM SPSS 21.
by MEYF
Referensi :
- Mendenhall, Sincinch. 1996. A Second Course In Statistics. Regression Analysis. Fifth Edition. Prentice Hall Internatiomal Edition.
- Priyatno, Duwi. 2010. Paham Analisa Statistik Data dengan SPSS. Mediakom. Yogyakarta.
- Sugiyono. 2009. Metode Penelitian Kuantitatif Kualitatif dan R & B. Bandung.
- Supranto, J. 2004. Analisis Multivariat : Arti dan Interpretasi. Rineka Cipta. Jakarta.
- Walpole, Ronald E. 1992. Pengantar Statistika Edisi ke-3. PT Gramedia Pustaka Utama. Jakarta.
- Shochrul dkk. Cara Cerdas Menguasai Eviews. Salemba Empat. 2011. Jakarta.
Selasa, 19 Agustus 2014
CONTOH UJI MULTIKOLINEARITAS DENGAN IBM SPSS 21
Berikut kita lakukan uji multikolinearitas dengan menggunakan software statistik IBM SPSS 21. Bersumber dari buku Prentice Hall International Edition, "A Second Course in Statistics : Regression Analisys".
Berdasarkan data tahunan dari The Federal Trade Comission (FTC) mengenai peringkat berbagai produk rokok lokal berdasarkan kandungan tembakau (mg), kandungan nikotin (mg), berat rokok (gram) dan karbon monoksida yang dihasilkan oleh rokok. Ahli bedah USA mempertimbangkan bahwa ketiga zat kimia tersebut sangat berbahaya bagi kesehatan perokok. Penelitian terdahulu menyimpulkan bahwa meningkatnya jumlah tembakau dan nikotin dalam rokok akan terjadi bersama-sama dengan meningkatnya karbon monoksida yang dihasilkan dari rokok saat digunakan. Berikut data yang diperoleh dari 25 merek rokok lokal di USA.









 |
| Source : Federal Trade Comission |
Model Regresi yang dapat dibentuk adalah :
Y' = a + b1X1 + b2X2 + b3X3
dimana
Y = Karbon monoksida (mg)
X1 = Kandungan tembakau (mg)
X2 = Kandungan nikotin (mg)
X3 = Berat rokok (gram)
Dari data di atas akan diuji apakah terjadi multikolinearitas atau tidak dengan menggunakan IBM SPSS 21. Berikut langkah-langkahnya :
1. Klik Start -> IBM SPSS 21
2. Pilih Variabel View dan isikan data seperti berikut :
3. Pilih Data View dan isikan data seperti berikut :
4. Klik Analyze -> Regression -> Linear
5. Pindahkan variabel Karbon monoksida (Y) ke kolom Dependent dan variabel Kandungan TAR (X1), Kandungan Nikotin (X2) dan Berat rokok (X3) ke kolom Independent.
6. Tandai Estimates, Model Fit dan Collinearity dianostics lalu klik Continue -> OK
7. Output pertama yang diperoleh adalah Variables Entered/Removed menunjukkan metode analisa regresi yaitu dengan metode Enter.
8. Output berikutnya adalah tabel Model Summary memperlihatkan nilai R Square dan Adjusted R Square yang tinggi yaitu 0,919 dan 0,907. Hal ini menunjukkan variabel-variabel bebas pada model dapat menjelaskan sekitar 90,7% variabel tak bebas pada model regresi tersebut.
9. Output berikutnya adalah tabel ANOVA menunjukkan nilai F=79,557 yang berguna untuk uji ketepatan model. Jika kita bandingkan dengan F tabel=3,07 (dengan k=3 dan v=25-(3+1)=21), maka nilai F=79,44 > F-tabel=3,07, sehingga model regresi secara keseluruhan adalah baik secara signifikan.
10. Output berikutnya adalah tabel Coefficients menunjukkan nilai parameter a, b1, b2 dan b3, sebagai berikut
- a = 3,210
- b1 = 0,965 menunjukkan nilai korelasi antara variabel X1 dan Y positif dengan sig. = 0,001
- b2 = -2,654 menunjukkan nilai korelasi antara variabel X2 dan Y negatif, hal ini bertentangan dengan penelitian terdahulu, dan nilai sig. = 0,503 yang tidak signifikan. Sehingga patut dicurigai adanya pelanggaran asumsi regresi.
- b3 = -1,47 menunjukkan nilai korelasi antara variabel X3 dan Y negatif, hal ini bertentangan dengan penelitian terdahulu, dan nilai sig. = 0,970 yang tidak signifikan. Sehingga patut dicurigai adanya pelanggaran asumsi regresi.
Hal ini pun didukung dengan nilai VIF pada kolom paling akhir, yang masing-masing variabel X2 dan X3 memiliki nilai VIF > 10 yang menunjukkan bahwa terjadinya pelanggaran asumsi multikolinearitas.
Dan jika kita hitung nilai R Square masing-masing parameter yang akan dibandingkan dengan nilai parameter, maka dapat diperoleh R Square = 1 - 1/(VIF)
- Parameter b1 = 0,965 maka nilai R Square = 1 - (1/21,631) = 1 - 0,046 = 0,956
- Parameter b2 = -0,2654 maka nilai R Square = 1 - (1/21,900) = 1 - 0,46 = 0,956
- Parameter b3 = -0,147 maka nilai R Square = 1 - (1/1,334) = 1 - 0,7496 = 0,2504
Seperti kita ketahui bahwa nilai parameter adalah nilai yang menunjukkan hubungan antara variabel bebas dengan variabel tak bebas dalam model regresi. Dan hal ini berhubungan dengan nilai koefisien determinasi R Square. Diperoleh bahwa nilai parameter b2 dan b3 memiliki perbedaan yang sangat jauh dengan nilai masing-masing R Square-nya. Hal ini patut dicurigai bahwa terjadinya multikolinearitas dalam model regresi.
by MEYF
Minggu, 17 Agustus 2014
UJI MUTIKOLINEARITAS (Test of Multicolinearity)
Misalkan model regresi Y' = a + b1X1 + b2X2, dimana pada variabel X1 dan X2 terdapat informasi yang redundan sehingga terjadinya hubungan atau korelasi antara variabel bebas X1 dan X2. Sehingga dalam hal ini akan mengganggu atau memberikan solusi yang tidak maksimum untuk model regresi. Kejadian ini disebut sebagai multikolinearitas.
Multikolinearitas adalah adanya hubungan atau korelasi linear yang sempurna atau pasti di antara beberapa atau semua variabel independen yang menjelaskan dari model regresi. Jika dalam model regresi terjadi multikolinearitas, maka akan muncul beberapa masalah serius dalam model. secara statistik masalah tersebut yaitu :
- Akan mengakibatkan meningkatnya nilai likelihood error dalam mengestimasi parameter, standar error, dll.
- Hasil model regresi akan membingungkan dan menyesatkan.
- Dengan melihat nilai VIF (Variance Inflation Factor) pada model regresi.
- Membandingkan nilai koefisien determinasi bk dengan nilai determinasi R^2 secara serentak.
- Melihat nilai Eigenvalue dan Condition Index.
Adapun beberapa indikator terjadinya multikolinearitas dalam model regresi :
Y' = a + b1X1 + b2X2, +...+bkXk,
- Adanya hubungan signifikan antara variabel bebas dalam model.
- Hasil uji-t yang tidak signifikan untuk semua parameter bk namun uji-F yang signifikan dalam uji ketepatan model.
- Adanya tanda yang berlawanan dengan apa yang diharapkan saat mengestimasi parameter. Misalnya saat menghitung korelasi antara Y dengan X1 diperoleh nilai korelasi R bertanda positif sedangkan korelasi dalam model regresi antara Y dan X1 (dilihat dari nilai parameter b1) diperoleh nilai bertanda negatif.
- Terjadinya perbedaan nilai yang besar antara koefisien regresi dengan nilai korelasi. Misalnya nilai korelasi antara variabel Y dengan X1 adalah r = 0,780 dan nilai signifikan. Sedangkan nilai koefisien regresi antara Y dan X1 b1 = 0,160 dan tidak signifikan.
- VIF = 1/(1-(Ri^2)) dimana Ri adalah koefisien determinasi dalam model. Jika nilai VIF lebih besar dari 10 maka terjadi multikolinearitas.
Jika hal di atas terjadi dalam model regresi Anda, patut untuk dicurigai bahwa terjadinya multikolinearitas dalam model regresi, sehingga terjadi pelanggaran asumsi.
Apa solusi yang dapat kita lakukan jika terjadi multikolinearitas?
- Menambah atau mengganti data sampel baru, memang hal ini akan mengeluarkan cost yang besar.
- Menghapus salah satu variabel prediktor yang mengalami multikolinearitas (kadang bisa mengakibatkan salah menghapus variabel).
- Mengabaikannya selama tidak menimbulkan masalah serius dalam model regresi. Namun hindari inferensi mengenai parameter bk dan batasi nilai variabel bebas agar tidak terjadi perbedaan mencolok antara nilai Y (nyata) dengan Y' (estimasi).
- Jika tujuan kita ingin membentuk hubungan sebab akibat antara Y dengan variabel bebas Xk maka gunakan Design of Experiment (Rancangan Percobaan).
- Untuk mengurangi rounding error dan menstabilkan koefisien regresi maka gunakan Ridge Regression untuk mengestimasi parameter bk.
- Mengganti metode analisis regresi dengan yang lebih advance seperti metode stepwise, PCR (principle component regression), dll.
Next session...tahap pengujian multikolinearitas dengan SPSS IBM 21.
by MEYF
Referensi :
- Priyatno, Duwi. 2010. Paham Analisa Statistik Data dengan SPSS. Mediakom. Yogyakarta.
- Sugiyono. 2009. Metode Penelitian Kuantitatif Kualitatif dan R & B. Bandung.
- Supranto, J. 2004. Analisis Multivariat : Arti dan Interpretasi. Rineka Cipta. Jakarta.
- Walpole, Ronald E. 1992. Pengantar Statistika Edisi ke-3. PT Gramedia Pustaka Utama. Jakarta.
- Shochrul dkk. Cara Cerdas Menguasai Eviews. Salemba Empat. 2011. Jakarta.
- Shochrul dkk. Cara Cerdas Menguasai Eviews. Salemba Empat. 2011. Jakarta.
UJI ASUMSI KLASIK REGRESI
Sebelumnya kita sudah membahas sebagian mengenai analisis regresi linear. Dapat kita rangkum beberapa langkah dalam analisis regresi linear :
- Membuat bentuk model regresi linear
- Mengambil data sampel
- Gunakan data sampel untuk mengestimasi parameter model linear
- Tentukan distribusi dari random error dan estimasi parameter lain yang tidak diketahui dari distribusi tersebut.
- Uji kegunaan model secara statistik
- Ketika model sudah sesuai maka model dapat digunakan untuk memprediksi atau mengestimasi.
Dalam regresi linear berganda yang berbasis OLS (Ordinary Least Square), persyaratan statistik yang harus dipenuhi sebelum melakukan analisis regresi linear berganda yaitu disebut dengan uji asumsi regresi. Namun analisis regresi linear yang tidak berdasarkan OLS tidak memerlukan uji asumsi, seperti regresi logistik.
Secara umum, uji asumsi untuk regresi dapat dikelompokkan atas :
1. Uji asumsi dasar regresi
- Uji normalitas
- Uji linearitas
- Uji homogenitas
2. Uji asumsi klasik regresi
- Uji multikolinearitas
- Uji heteroskedastisitas
- Uji autokorelasi
- Uji normalitas
Tidak ada ketentuan urutan uji mana yang harus dilakukan terlebih dahulu. Uji asumsi regresi ini dilakukan agar hasil analisa regresi yang diperoleh lebih akurat. Jika terdapat salah satu asumsi yang tidak terpenuhi, maka ada kecurigaan bahwa analisis yang diperoleh kurang akurat, error yang besar, koefisien yang tidak minim, variabel bebas yang tidak terdeteksi sehingga bisa menyebabkan kesalahan interpretasi.
Untuk itu jika asumsi regresi tidak terpenuhi, dilakukan beberapa hal agar dapat memenuhi uji asumsi tersebut, sebagai contoh uji normalitas, jika tidak terpenuhi maka salah satu solusinya adalah menambah jumlah sampel atau melakukan transformasi variabel, dll. Dan jika asumsi dasar masih tidak terpenuhi maka selanjutnya adalah mengubah analisis data regresi dengan analisis data yang lain yang dianggap lebih tepat.
Uji Normalitas (Test of normality) digunakan untuk mengetahui apakah populasi data berdistribusi normal atau tidak. Biasanya digunakan untuk data berskala ordinal, interval atau pun rasio. Uji yang biasa digunakan adalah uji Liliefors melalui nilai pada Kolmogorov Smirnov. (See this Uji Liliefors)
Uji Linearitas (Test of Linearity) digunakan untuk mengetahui apakah dua variabel mempunyai hubungan yang linear atau tidak secara signifikan. Pada SPSS diperoleh melalui ANOVA dengan memilih icon "Test for Linearity".
Uji Homogenitas (Test of Homogenity) digunakan untuk mengetahui apakah beberapa varian populasi data adalah sama atau tidak. Pada SPSS diperoleh melalui ANOVA dengan memilih Test of Homogenity, dan hasilnya bisa dilhat dari nilai Levene Test dimana semakin kecil nilainya maka semakin besar homogenitasnya.
Uji Multikolinearitas (Test of Multicolinearity) digunakan untuk mengetahui ada atau tidaknya hubungan linear antar variabel independen dalam model regresi. Pada SPSS diperoleh melalui Linear Regression dengan memilih icon Collinearity diagnostics, dan hasilnya ada pada kolom VIF yang memiliki nilai kurang dari 5 maka tidak terdapat multikolinearitas.
Uji Heteroskedastisitas (Test of Heteroskedasticity) digunakan untuk mengetahui ada atau tidaknya ketidaksamaan varian dari residual pada model regresi. Pada SPSS diperoleh melalui Bivariate Correlation.
Uji Autokorelasi (Test of Autocorrelation) digunakan untuk mengetahui ada atau tidaknya korelasi antara satu residual pengamatan dengan residual pengamatan lainnya pada model regresi. Pada SPSS diperoleh melalui Linear Regression dengan memilih icon Durbin-Watson.
Dalam regresi linear ada empat asumsi yang harus dipenuhi (see this Analisis Regresi Sederhana), yaitu :
- Masing-masing variabel bebas adalah linear dan tidak berkorelasi.
- Random error memiliki variansi konstan.
- Random error saling bebas (independen).
- Random error memiliki distribusi normal dengan mean 0 dan standar deviasi tetap.
Masing-masing asumsi dapat diuji dengan uji asumsi klasik di atas, yaitu
- Asumsi 1 : Uji normalitas
- Asumsi 2 : uji heteroskedastisitas
- Asumsi 3 : Uji autokorelasi
- Asumsi 4 : Uji multikolinearitas
Untuk selanjutnya akan kita bahas satu-persatu.
Semoga bermanfaat ;)
by MEYF
Referensi
- Mendenhall, Sincinch. 1996. A Second Course In Statistics. Regression Analysis. Fifth Edition. Prentice Hall Internatiomal Edition.
- Priyatno, Duwi. 2010. Paham Analisa Statistik Data dengan SPSS. Mediakom. Yogyakarta.
- Sugiyono. 2009. Metode Penelitian Kuantitatif Kualitatif dan R & B. Bandung.
- Supranto, J. 2004. Analisis Multivariat : Arti dan Interpretasi. Rineka Cipta. Jakarta.
- Walpole, Ronald E. 1992. Pengantar Statistika Edisi ke-3. PT Gramedia Pustaka Utama. Jakarta.
- Shochrul dkk. Cara Cerdas Menguasai Eviews. Salemba Empat. 2011. Jakarta.
- Shochrul dkk. Cara Cerdas Menguasai Eviews. Salemba Empat. 2011. Jakarta.
Senin, 11 Agustus 2014
TEKNIK INTERPOLASI LINIER
Dalam matematika fungsi dan titik, kita kenal istilah interpolasi yaitu teknik mencari harga suatu fungsi pada suatu titik di antara dua titik yang nilai fungsi pada ke-2 titik tersebut sudah diketahui.
Jenis-jenis interpolasi terbagi atas empat, yaitu :
- Interpolasi Linier
- Interpolasi Kuadrat
- Interpolasi Lagrange
- Interpolasi Newton
Dalam hal ini kita akan membahas mengenai teknik interpolasi linier karena dalam kasus statistik lebih sering menggunakan interpolasi linier dalam menentukan nilai kurva tabel.
Perhatikan gambar berikut ini :

Kurva yang terdiri dari titik-titik : (xk, yk) ; (x, y*) dan (xk+1, yk+1).
Dalam hal ini titik y* tidak diketahui dan akan kita cari menggunakan teknik interpolasi linier.
Melalui persamaan garis linier maka kita akan memperoleh nilai y*, yaitu :

Sebagai contoh penentuan nilai tabel pada kurva normal (Tabel Normal Standar).
Berapakah nilai Z jika taraf signifikansinya 0,7100 ?
Dalam hal ini jika kita lihat tabel kurva normal. Nilai taraf nyata 0,7100 tidak terdapat di dalam tabel. Namun kita dapat menentukannya melalui teknik interpolasi, yaitu dengan mencari nilai taraf signifikansi yang mengapit nilai 0,7100.
Kita peroleh nilai tersebut :
0,7088 -> Z = 0,55
0,7123 -> Z = 0,56
misalkan 0,7100 -> Z = x
Perhatikan gambar berikut ini :

Gunakan persamaan di atas untuk menentukan nilai x

Jadi diperoleh nilai Z = 0,5534 untuk taraf signifikansi 0,7100.
Contoh lain pada tabel Liliefors. (Tabel Uji Liliefors)
Berapakah nilai L jika jumlah sampel n = 27?
n = 25 -> L = 0,173
n = 30 -> L = 0,161
misalkan n = 27 -> L = x
Perhatikan gambar berikut ini :

Maka nilai x menggunakan interpolasi linier sebagai berikut :

Jadi diperoleh nilai L = 0,1658 = 0,166.
Contoh pertama pada tabel kurva normal memiliki kemiringan garis positif dan pada tabel Liliefors memiliki kemiringan garis negatif.
by MEYF
Jumat, 08 Agustus 2014
CONTOH ANALISIS REGRESI LINEAR BERGANDA (DUA VARIABEL) MENGGUNAKAN IBM SPSS 21
Kita gunakan contoh sebelumnya pada artikel Contoh Perhitungan Manual Analisis Linear Berganda Dua Variabel. Terdapat satu variabel tak bebas Y dan dua variabel bebas X1 dan X2.
Bentuk umum persamaan regresi linear berganda kasus tersebut adalah :
Selanjutnya kita akan menentukan nilai dari a, b1 dan b2.

3. Pada Data View input data seperti berikut :

4. Klik Analyze -> Regression -> Linear



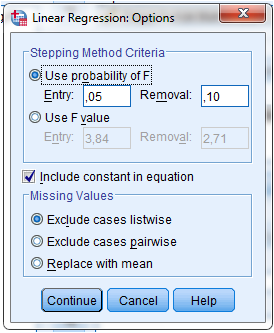
7. Pilih Options masukkan nilai taraf signifikansi dalam hal ini kita pilih 5% sehingga ketik 0,05 pada kolom Entry. Tandai Include Constant in Equation.

Dari output disamping menjelaskan mengenai output dari method yang kita pilih yaitu Enter.

Dari output di atas pada tabel Model Summary diperoleh nilai koefisien determinasi Rsquared = 0,942 yang berarti sekitar 94,2% variasi sampel harga minyak dan pendapatan dapat menjelaskan variasi variabel permintaan minyak goreng. Nilai ini merupakan nilai yang tinggi dan mencerminkan terjadinya hubungan kuat antara variabel bebas X1 dan X2 dan variabel tak bebas Y.
Nilai Adjusted Rsquared pun menunjukkan nilai yang tinggi yaitu 0,929. Nilai ini sama-sama boleh digunakan dengan Rsquared. Jika kita ingin menggeneralisasikannya ke populasi dan responden yang dipilih acak maka kita gunakan Adjusted Rsquare dan jika sampel tidak acak kita gunakan sebaiknya Rsquared. Nilai keduanya akan mendekati nilai yang sama jika sampel yang diambil berukuran besar.

Pada kolom Coefficients diperoleh nilai koefisien/parameter regresi linear berganda a = 12,775, b1 = -0,001 dan b2 = -0,488. Sehingga persamaan regresi yang diperoleh adalah :

Dengan menggunakan IBM SPSS 21, maka kita dapat melakukan analisis linear berganda pada data tersebut dengan tujuan untuk melihat pengaruh X1 dan X2 terhadap Y dan sekaligus dapat memprediksi nilai Y jika X1 dan X2 diberikan.
Bentuk umum persamaan regresi linear berganda kasus tersebut adalah :
Y' = a + b1X1 + b2X2
Selanjutnya kita akan menentukan nilai dari a, b1 dan b2.
Berikut tahap-tahap yang dapat dilakukan :
1. Klik Start -> IBM SPSS 21
2. Pada Variabel View isikan data seperti berikut :
2. Pada Variabel View isikan data seperti berikut :
3. Pada Data View input data seperti berikut :
4. Klik Analyze -> Regression -> Linear
5. Pada kolom Linear Regression pindahkan varibel tak bebas Y, Permintaan Minyak ke kolom Dependent, dan pindahkan variabel bebas X1, Harga Minyak dan X2, Pendapatan ke kolom Independent.
6. Klik Statistics centrang tiga item berikut lalu klik Continue.
- Estimates untuk menentukan nilai parameter a, b1 dan b2
- Model Fit: untuk uji ketepatan model regresi linier
- R Squared Change : untuk menentukan nilai R2
7. Pilih Options masukkan nilai taraf signifikansi dalam hal ini kita pilih 5% sehingga ketik 0,05 pada kolom Entry. Tandai Include Constant in Equation.
Pada kolom ini berfungsi untuk uji-F, untuk menguji pengaruh variabel bebas X1 dan X2 secara bersamaan terhadap variabel tak bebas Y. (Regresi Linear Berganda)
Pada Missing Values
- Exclude cases listwise :hanya data yang valid untuk semua variabel yang ikut dianalisis
- Exclude cases pairwise :menganalisis koefisien korelasi dan seluruh cases yang berharga valid dari dua variabel yang dikorelasikan.
- Replace with mean : Semua data dianalisis dan untuk data yang kosong digantikan dengan rata-rata variabel tersebut.
Dari output disamping menjelaskan mengenai output dari method yang kita pilih yaitu Enter.
Nilai Adjusted Rsquared pun menunjukkan nilai yang tinggi yaitu 0,929. Nilai ini sama-sama boleh digunakan dengan Rsquared. Jika kita ingin menggeneralisasikannya ke populasi dan responden yang dipilih acak maka kita gunakan Adjusted Rsquare dan jika sampel tidak acak kita gunakan sebaiknya Rsquared. Nilai keduanya akan mendekati nilai yang sama jika sampel yang diambil berukuran besar.
Pada kolom Coefficients diperoleh nilai koefisien/parameter regresi linear berganda a = 12,775, b1 = -0,001 dan b2 = -0,488. Sehingga persamaan regresi yang diperoleh adalah :
Y' = 12,775 -0,001X1 - 0,488X2
Dan untuk uji-t diambil dari kolom t dan sig. pada variabel X1 dan X2. Tabel ini berguna untuk pengujian parameter secara parsial, apakah variabel bebas secara terpisah berpengaruh signifikan terhadap variabel tak bebas.
a. Uji parameter b1
Hipotesis Uji :
Ho : b1 = 0
Ha : b1 ≠ 0
Taraf Signifikansi :
Pilih nilai a = 5%
Daerah Kritis :
Dengan nilai signifikansi 5% dan derajat bebas df = n-2 = 12-2 = 10, maka diperoleh t-tabel = 2,228.
Statistik Uji :
Diperoleh t-hitung = -1,486 dan nilai p-value = 0,172
Keputusan :
Nilai t-hitung = -1,486 > t-tabel = -2,228 atau nilai p-value = 0,172 > 0,05.
Jadi Ho diterima dan Ha ditolak.
Kesimpulan :
Dengan signifikansi 5% ternyata harga minyak goreng tidak berpengaruh terhadap permintaan minyak goreng tersebut. Hal ini minyak goreng adalah kebutuhan pokok yang sangat dibutuhkan oleh semua orang dalam memenuhi kebutuhan makanannya. Berapapun harganya permintaan akan minyak gorengpun tetap ada.
b. Uji parameter b2
Hipotesis Uji :
Ho : b2 = 0
Ha : b2 ≠ 0
Taraf Signifikansi :
Pilih nilai a = 5%
Daerah Kritis :
Dengan nilai signifikansi 5% dan derajat bebas df = n-2 = 12-2 = 10, maka diperoleh t-tabel = 2,228.
Statistik Uji :
Diperoleh t-hitung = -3,776 dan nilai p-value = 0,172
Keputusan :
Nilai t-hitung = -3,776 < t-tabel = -2,228 atau nilai p-value = 0,004 < 0,05.
Jadi Ho ditolak dan Ha diterima.
Kesimpulan :
Dengan signifikansi 5% ternyata pendapatan konsumen berpengaruh terhadap permintaan minyak goreng tersebut.
Tabel ANOVA di atas adalah salah satu untuk menguji ketepatan model. Apakah variabel bebas secara bersama-sama mempengaruhi variabel tak bebas. Kita menggunakan uji F.
Hipotesis Uji :
Ho : b1 = b2 = 0
Ha : Terdapat bi ≠ 0 dengan i = 1 dan 2
Taraf Signifikansi :
Pilih nilai a = 5%
Daerah Kritis :
Dengan nilai signifikansi 5%, derajat bebas pembilang dk = 2 dan derajat bebas penyebut df = n-k-1 = 12-2-1 = 9, maka diperoleh F-tabel =19,39.
Statistik Uji :
Diperoleh F-hitung = 73,312 dan nilai p-value = 0,000
Keputusan :
Nilai t-hitung = 73,312 > F-tabel = 19,39 atau nilai p-value = 0,000 < 0,05.
Jadi Ho ditolak dan Ha diterima.
Kesimpulan :
Dengan signifikansi 5% harga minyak goreng dan pendapatan konsumen secara bersama-sama berpengaruh terhadap permintaan minyak goreng.
by MEYF







